The given coefficients in this sample are random. In your case you should've already calculated your own coefficients according to the exercise. All the samples are using the same coefficients as shown below. For further reading of scheduling operations, binding etc. see lecture notes.
| Coefficients | Coefficient value |
|---|---|
| c1 & c9 | 0,125 |
| c2 & c8 | 0,25 |
| c3 & c7 | -0,75 |
| c4 & c6 | 1,25 |
| c5 | 1,0 |
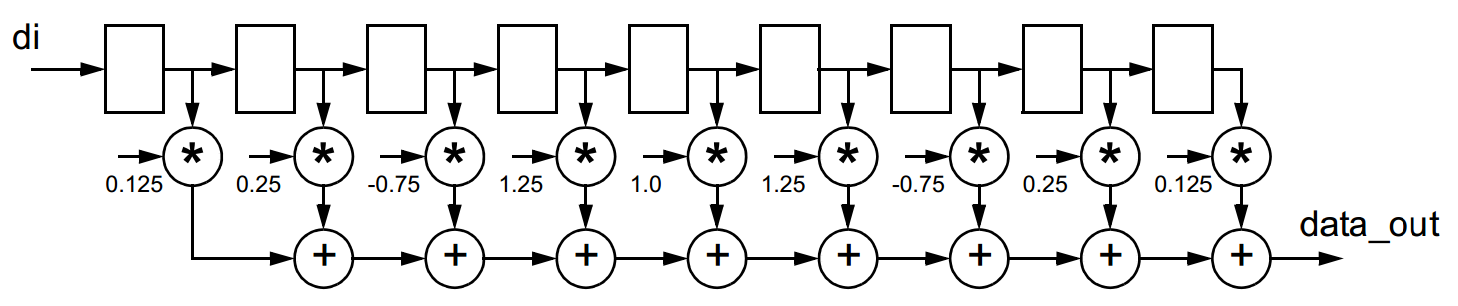
Figure 1. 9-tap Finite Impulse Response (FIR) filter
According to Figure 1 the formula to calculate data_out is:
data_out = 0,125 * di-0 + 0,25 * di-1 - 0,75 * di-2 +
1,25 * di-3 + 1,0 * di-4 + 1,25 * di-5 - 0,75 * di-6 +
0,25 * di-7 + 0,125 * di-8
Alltogether 9 multiplications and 8 additions/subtractions.
After reduction of the equation we get:
data_out = 0,125 * (di-0 + di-8) + 0,25 * (di-1
+ di-7) - 0,75 * (di-2 + di-6) + 1,25 * (di-3 + di-5)
+ 1,0 * di-4
Alltogether 4 multiplications and 8 additions/subtractions. The multiplication with 1,0 is figurative.
Due to the fact that multiplication is too expensive (time!!!) we should try to substitute it with some other operation. So we use shift-add trees to substitute multiplication with shifting and adding.
Alltogether 12 additions/subtractions. After common sub-expression eliminations (no point to add di-2 + di-6 and di-3 + di-5 twice) 8 additions and 2 subtractions which means 10 operations. The operations are scheduled among 4 steps. The result of every operation is saved always in the same register (reg1, reg2, ..., reg4). Multiplexers in adder/ subtractor inputs are not optimized.
| Step | add #1 | add #2 | add #3 | sub #4 |
|---|---|---|---|---|
| 1 | reg1 = di-1 + di-7 | reg2 = di-2 + di-6 | reg3 = di-3 + di-5 | - | 2 | reg1 = di-0 + di-8 | reg2 = di-4 + (reg1 >> 2) | reg3 = reg3 + (reg3 >> 2) | reg4 = reg2 - (reg2 >> 2) |
| 3 | reg1 = (reg1 >> 3) + reg2 | - | - | reg4 = reg3 - reg4 |
| 4 | reg1 = reg1 + reg4 | - | - | - |
In the next part 4 similar designs were eleborated which all have been tested with three different synthesise strategies. The sample codes and synthesise strategies are all shown. To sum up the results check Table 5.
Most of the students need an adder-subtractor to be able to fulfill the required RTL task. It is highly recommended to use the code example on lecture slide 52. Be aware that the code there is a sequential code. Also you should understand the principle of the code to be able to implement it later. Solutions which produce more than one adder in case of adder-subtractor synthesis will be rejected!
| # | Design description | Code |
|---|---|---|
| 1 | Firstly VHDL code which more or less corresponds to the behavioral RTL. Functions add1, add2, add3 and sub1 are used to force the synthesizer to use the same modules. However it didn't work and in the best case the filter had 4293 gates (2032 for combinational and 2261 for registers). Delay was less than 20 ns (19,98). | Design#1 |
| 2 | Much better result can be achieved when computational units are coded as separate processes. The result introduces a pseudo finite state machine (FSM) which in turn makes the structure way more confusing. However the results of the synthesis are way better - 3474 gates (1192 for combinational and 2282 for registers). Delay was the same as in case of solution 1 - 19,98 ns. | Design#2 |
| 3 | The best result was achieved when compared to the solution 2 FSM state transition function and registers were added. Result of the synthesis - 3248 gates (1181 for combinational and 2067 for registers). Delay 19,99 ns. | Design#3 |
| 4 | Last solution is even more precise description of the last RTL where in the data part single adders/subtractors and multiplexers are presented in detail. The results are practically the same as in case of the solution 3. Area - 3248 gates (1182 for combinational and 2066 for registers). Delay 19,99 ns. | Design#4 |
| 5 | Piplined, scheduling & binding | Design#5 |
| 6 | Out-of-order calculations, scheduling & binding | Design#6 |
| 7 | Extra optimization on MUX | Design#7 |
The codes for the strategies are shown although as proposed in the Design Vision guide all should be doable using GUI.
| Strategy #1 | Strategy #2 | Strategy #3 |
|---|---|---|
| Initial transition, flattening hierarchy, high optimization. | Initial transition, flattening hierarchy, medium optimization. | Initial medium optimization, hierarchy is retained. |
| create_clock -name "clk" -period 20 -waveform {"0" "10"} {"clk"} | ||
|
compile -map_effort low
ungroup -all -flatten set_max_area 2000 compile -map_effort high report_area report_timing |
set_max_area 2000
compile -map_effort low ungroup -all -flatten compile -map_effort medium report_area report_timing |
set_max_area 2000
compile -map_effort medium report_area report_timing |
As can be seen on Table 5 the best results are provided by synthesis strategy #3. In case of RTL codes design 3 and design 4 have total area the same however delay in case of design 4 is 5 ns smaller. While examining the design codes it looks simpler in case of design 3 than design 4.
| Design | Strategy | Intermediate area [comb.+reg.=total] | Final area [comb.+reg.=total] | Differnece | Delay [ns] |
|---|---|---|---|---|---|
| Design 1 | #1 | 2328 + 2074 = 4402 | 1929 + 2069 = 3998 | +20% | 19,98 |
| #2 | 2285 + 2071 = 4356 | 2064 + 2072 = 4136 | +24% | 19,60 | |
| #3 | 2248 + 2073 = 4321 | +30% | 19,99 | ||
| Design 2 | #1 | 1359 + 2275 = 3634 | 1387 + 2276 = 3663 | +9,9% | 19,99 |
| #2 | 1340 + 2275 = 3615 | 1397 + 2276 = 3673 | +10,2% | 19,99 | |
| #3 | 1322 + 2275 = 3597 | +8% | 19,99 | ||
| Design 3 | #1 | 1308 + 2062 = 3370 | 1354 + 2063 = 3417 | +2,6% | 20,00 |
| #2 | 1301 + 2062 = 3363 | 1382 + 2063 = 3445 | +3.4% | 20,00 | |
| #3 | 1270 + 2062 = 3332 | 100% | 19,98 | ||
| Design 4 | #1 | 1381 + 2062 = 3443 | 1393 + 2062 = 3455 | +3,7% | 19,99 |
| #2 | 1360 + 2062 = 3422 | 1449 + 2062 = 3511 | +5,4% | 19,99 | |
| #3 | 1354 + 2062 = 3416 | +2,5% | 20,00 | ||
| Design 5 | #1 | 1145 + 2345 = 3490 | 1094 + 2346 = 3440 | +3,2% | 19,98 |
| #2 | 1123 + 2345 = 3468 | 1128 + 2346 = 3474 | +4,3% | 19,98 | |
| #3 | 1096 + 2345 = 3441 | +3,3% | 19,75 | ||
| Design 6 | #1 | 1166 + 1950 = 3116 | 1143 + 1951 = 3094 | -7,1% | 19,99 |
| #2 | 1137 + 1950 = 3087 | 1166 + 1951 = 3117 | -6,5% | 19,98 | |
| #3 | 1125 + 1950 = 3075 | -7,7% | 19,65 | ||
| Design 7 | #1 | 1142 + 1950 = 3092 | 1116 + 1951 = 3067 | -8,0% | 19,92 |
| #2 | 1114 + 1950 = 3064 | 1145 + 1951 = 3096 | -7,1% | 19,99 | |
| #3 | 1104 + 1951 = 3055 | -8,3% | 19,93 |